We Built the Vaultless Tokenization Fix Where It Belongs — Inside Cloudera
- Jul 24, 2025
- 5 min read
Updated: Jul 30, 2025

We’ve been building Big Data platforms for more than two decades. And if there’s one thing we’ve learned after helping deploy over 400 enterprise data lakes across EMEA and APAC, it’s this: sensitive data is everywhere, and the way we’ve been told to protect it no longer works.
Tokenization was supposed to make data protection easier. But the dominant models were built for a different era. Siloed systems, static pipelines, and vaults sitting outside the platforms just to be secured. It’s not scalable. It breaks pipelines. It slows teams down. And somehow, it became the standard that we’ve never accepted as the future.
The Cloudera engineering team saw it too, which is exactly why, together, we built a fix —a vaultless tokenization solution that runs natively inside Cloudera.
Jump to:
We’ve seen data ambition hit a wall
When we started Bluemetrix, we weren’t thinking about tokenization. We were helping global enterprises build secure, scalable data platforms on Hadoop and Cloudera. And for years, it had worked well until security began slowing down modernization efforts.
The breaking point looked different for every organisation. For some, it was the push toward GenAI. For others, cloud migration, regulatory pressure, or the need to share sensitive data across business units. But the pattern was always the same: as soon as a strategic data goal emerged, security team stepped in and asked: “How secure is the data?” That single question, though necessary, often halted progress. And it was the moment when the momentum stalled – and the wall became real.
Suddenly, data architects were left carrying the weight. They turned to Cloudera, where tokenization was part of the answer. However, the legacy, bolt-on model they were handed wasn’t built for the environment they were already running. Instead of unblocking innovation, it became another layer to work around.
From bolt-on to built-In
There’s a common misconception that modern tokenization can’t scale on Cloudera, but that’s entirely backwards. Cloudera isn’t the barrier to tokenization. It’s the reason we can finally do it right.
Cloudera Data Platform (CDP) gives enterprises a single, unified foundation to manage and govern data across legacy systems, cloud services, and modern analytics tools. It combines scalable compute with centralized policy enforcement and makes it possible to manage security within the data platform, not around it.
With integrated tools like Spark, Ranger, Atlas, and KMS, you could finally have a security architecture that’s powerful, consistent, and ready to scale. The only thing missing was a tokenization solution designed to live inside that architecture.
And we’re shipping it today.
A major step towards Cloudera Native Tokenization
Today, we’re showcasing three powerful security capabilities in SecureToken that move us from brittle, ad hoc data protection to scalable, enterprise-grade tokenization built in Cloudera:
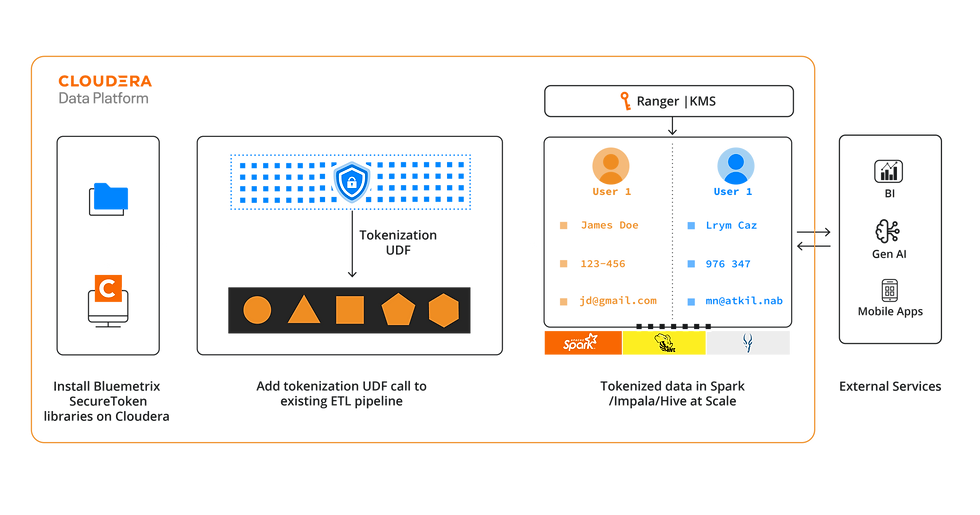
Vaultless Tokenisation solves the fundamental issue of securing data without rendering it unusable. Instead of relying on external systems, SecureToken performs format-preserving, NIST-compliant tokenization directly inside the Cloudera platform. No vaults, no data movement, and no compromise to query structure. It supports both reversible and irreversible tokenization, all the while maintaining the original data type and referential integrity.
Think of a global financial services team with dozens of pipelines and downstream joins built on sensitive account data. Without format-preserving tokenization, they’d be rewriting SQL logic and duplicating datasets just to stay compliant. With SecureToken, they apply a policy once and keep everything downstream working as-is.
This isn’t a workaround—it’s a clean, efficient solution that integrates security without sacrificing performance or usability.

AMP-Based Deployment eliminates the lengthy rollout cycles that typically come with enterprise data protection tools. SecureToken is packaged as a native Cloudera AMP, with built-in UDFs that plug directly into Spark, Hive, and Impala. That means teams don’t need to rewrite logic, modify existing pipelines, or wait weeks for deployment.
Unlike a typical scenario, it will only take just 1–2 days to go from installation to production. For a data platform team managing tokenization across hundreds of tables and multiple business units, this kind of deployment speed is transformative. You can roll out consistent protections quickly, using predefined templates across various data sources, and make updates without creating downtime or drift.
This targeted approach transforms the tokenization rollout from a months-long project into a lightweight, repeatable step in the data pipeline. And because protections are defined centrally and deployed natively, platform teams can onboard new data sources in hours—not weeks—while maintaining full auditability across every environment.
Teradata Integration is where SecureToken extends Cloudera’s protection model into the broader enterprise. We’ve made it possible to apply scalable, policy-driven tokenization to Teradata, using the same governance controls already in place. This matters because many enterprises store sensitive data in both platforms yet lack a unified way to secure data once it leaves its source environment.
When data operates in SecureToken, the process is simple but powerful. Once tokenized, the data remains fully usable inside Teradata. A native UDF allows teams to read and de-tokenize values directly within SQL, using familiar workflows. The function connects to RangerKMS in Cloudera to retrieve encryption keys securely at runtime, so governance stays centralized while access remains local. There’s no need to replicate policies or maintain separate systems.
This model allows Cloudera to remain the single point of control, even when the data resides elsewhere. Your governance teams can now define tokenization policy once, and that policy travels with the data. The result is a foundation for enterprise-wide data protection that scales with your ecosystem, ensuring broader compliance coverage across the full data estate.
Tokenization is finally moving where it belongs
We’ve seen this coming. Enterprises have poured millions of dollars of investment into tokenisation, attempting to weave it across vaults, services, and stitched-together policies. But anyone managing data at scale knows the reality: it’s been a slow, costly process that often spirals beyond original budgets.
That’s no longer acceptable. Security teams want enforcement. AI teams need access to structured data. Compliance teams are done accepting “masked” as a synonym for “protected.” And in Cloudera environments with hundreds of nodes and thousands of pipelines, data teams are asking to tokenize 50, 100, even 200 columns.
This changes how we think about tokenization. It’s no longer a post-processing step. It has to be embedded in the query engine, in the runtime, in the policy layer.
When a platform team says, “We need to protect customer data across Spark, and it all needs to run by Monday,” the system has to be able to ask:
What’s the policy?
What’s the format?
Which key?
Who gets access?
Vaultless Tokenization at the platform level is the only way to meet today’s demands for speed, security, and control.
How to move toward native vaultless tokenization in Cloudera
If you’re leading data protection or security efforts in Cloudera and still operating with the legacy models, we’ve called out earlier, here’s how to start shifting toward a native model:
Confirm Cloudera Integration. Is it built to run inside the platform?
Verify Enforcement Coverage. Does it run natively in Spark, Hive and Impala?
Integrated Governance Control. Do Ranger and KMS manage access and encryption centrally?
It’s time to rethink what’s possible when your tokenization solution belongs inside your platform. With Cloudera as the foundation and SecureToken as the vaultless engine, tokenization becomes what it was always meant to be: invisible, powerful, and built to move with your data without holding it back.
Read full whitepaper here or speak to our team.


