Building Secure Vaultless Tokenization on Cloudera
- May 1
- 7 min read
Discover how Bluemetrix built SecureToken, a highly scalable, Cloudera-native vaultless tokenization solution protects sensitive data and reduces compliance scope in a cost-effective manner.

From protecting personally identifiable information in financial services to securing patient data in healthcare and safeguarding sensitive government datasets, enterprises are under growing pressure to protect data without slowing down analytics, AI, and operational workflows.
Traditional vault-based or vaultless approaches to tokenization often create new operational challenges. Separate token vaults add more infrastructure to manage, more systems to secure, and even more latency into AI pipelines.
So, how can organisations protect sensitive data at scale, reduce compliance scope and preserve data usability all at once?
This article outlines the key principles behind vaultless tokenization, why it matters for modern enterprise architectures, and how Bluemetrix built a highly scalable and secure Vaultless Tokenization on Cloudera to help organizations secure sensitive data by design.
What is Vaultless Tokenization, and Where Does it Get Used?
Data tokenization is a form of pseudonymisation that replaces sensitive data with unique tokens. Unlike masking, tokenization can support reversibility for approved users and systems, making it useful in workflows where the original value may still need to be accessed under strict controls.
Vaultless Tokenization takes this a step further.
Instead of relying on a separate mapping store and an external vault, tokens in the vaultless approach are generated cryptographically from the original value and the governing key material. This eliminates the need for a standalone token vault while still enabling secure and controlled reversibility.
From a real-world perspective, it is especially valuable in production environments where sensitive data must remain protected but still usable in large-scale data systems. Common use cases include:
Financial services, where organisations need to protect customer identifiers, account-related data, and regulated personal information.
Healthcare, where providers and research environments need to de-identify patient data while preserving controlled access for approved workflows.
Public sector and government, where agencies need to secure classified or highly sensitive datasets used for analytics and strategic decision-making.
This model is increasingly relevant because enterprises need security controls that fit modern distributed data architectures rather than forcing data through separate legacy protection layers.
What Are the Essential Building Blocks of a Vaultless Tokenization Platform?
A vaultless tokenization platform needs more than encryption alone. To operate effectively in enterprise environments, it must combine strong cryptography, centralised governance, controlled reversibility, and operational scale.
At the centre of SecureToken is the SecureToken Management Server, which acts as the control plane built on three fundamental components:
Centralised Security Operations
The first component is a central management layer that governs both tokenization and/or de-tokenization policies. This is where administrators define how sensitive data should be protected and under what conditions those values can be reversed. This layer is essential because it allows organisations to apply consistent security policies in pipelines, workloads, and teams without relying on fragmented configurations.
Encryption Keys
The second component is secure key lifecycle management. This component handles the creation, storage, and retrieval of encryption keys for authorised systems and users. The authorised caller receives only the key assigned for their permitted security operation on Ranger KMS, while the sensitive payload remains entirely inside the secure boundary.
Auditability and Reporting
The third component is an immutable audit layer. For all administrative actions and events happen within SecureToken, including policy changes, key operations, and data assets, SecureToken records a detailed, tamper-resistant audit trail that helps security teams maintain operational accountability and simplify compliance reporting.
These reports also feed a real-time monitoring dashboard that surfaces timestamps, action types, severity levels, and access events for enterprise data environments.
What Makes SecureToken Vaultless Tokenization Different?
Many organizations already understand the value of protecting sensitive data. The real challenge is doing it in a way that works across modern data platforms.
SecureToken vaultless tokenization is different because it is not just about replacing data values. It is about embedding protection into the architecture itself while preserving performance, usability, and control.
That means applying principles such as:
Data minimization, so raw sensitive values are exposed only when absolutely necessary.
Strict access control, so only authorized systems and users can invoke de-tokenization or other security options.
Cryptographic protection, so sensitive values are secured both at rest and in transit.
Operational scalability, so protection grows with the data platform rather than becoming a bottleneck beside it.
This security posture becomes even more imperative in large-scale lakehouse environments, where data constantly moves in and out, or from ingestion pipelines, ETL processes, analytics engines to downstream business workflows. In hybrid environments, separate vault-based designs can bring friction, latency, and synchronisation challenges that make secure operations harder.
SecureToken Vaultless tokenization addresses these challenges by reducing infrastructure dependencies while still maintaining strong perimeters over how sensitive data is protected and accessed.
How Bluemetrix Delivers Secure Vaultless Tokenization on Cloudera
Building secure vaultless tokenization requires more than a security feature. It requires a platform-level approach that fits how enterprise data systems already operate.
Bluemetrix built SecureToken as a Cloudera-native solution designed to ensure security, governance, and scalability throughout the data lifecycle.
As of today, SecureToken has been deployed in various industries, from enforcing PII tokenization and least-privilege, to enabling secure federated research on de-identified patient records, to safeguarding classified government national datasets for strategic analysis and predictive modelling.
The security model enforces a Zero Trust approach with continuous monitoring and a multi-layered defence strategy. Role-based access control governs the use and exposure of sensitive data, with granular column-based security enforced by defined tokenization, and ranger policies. Centralised key generation and storage are tightly integrated with Ranger KMS and Cloudera Manager. The principle of least privilege is applied at every layer, and encryption of tokenized data is enforced both at rest and in transit.
Prior to adopting a Cloudera-native tokenization approach, organisations typically relied on external proxy solutions that required behind-the-scenes effort to maintain compounded latency on every operation, and infrastructure dependencies, which are difficult to scale and synchronise across environments. These issues are now addressed through SecureToken's compute processing model and native integration with Cloudera environments. The SecureToken Management Server, along with KMS integration and Cloudera-native UDFs, enables horizontal scaling and consistent enforcement through all data services on a unified management layer.
How the Architecture Works in Practice
Figure 1 shows the SecureToken architecture within the Enterprise Data Environment and Cloudera Platform.

The key components and their interactions are as follows.
SecureToken sits at the centre of the architecture, within the Enterprise Data Environment. It serves as the central management system for data security operations, the DEK registry, and the audit repository. All tokenization profiles, key requests, and audit entries pass through this component.
The Security Admin first configures tokenization profiles, manages encryption key lifecycle, and reviews audit logs through an HTTPS-secured management interface. Profile configuration is centralised and immutable once created. Once a profile is locked, its behaviour is assured removing configuration drift across environments.
The External ETL system orchestrates data pipelines and triggers Apache Spark jobs. It communicates with SecureToken via a local agent over sockets, requesting encryption keys and pushing audit records. Job submission to the Spark and Apache Hive engine occurs via Livy and JDBC.
The Identity Provider (LDAP/Active Directory) handles user and system authentication via LDAP and Kerberos. SecureToken authenticates callers through this layer before any data security operation is authorised.
The Cloudera platform cluster contains the compute and key management layer:
The Spark/Hive Engine processes data using native UDFs and the local agent. It reads from and writes to the Data Lake over HDFS and Ozone (S3).
Cloudera Manager handles lifecycle management and monitoring of the cluster. SecureToken monitors cluster health and manages the agent lifecycle through Cloudera Manager via API and Parcels.
Apache Ranger KMS stores Master Keys (Key Encryption Keys, or KEKs). SecureToken wraps and unwraps DEKs against Ranger KMS via a REST interface, meaning data encryption keys are always envelope-encrypted and never persisted in plaintext.
The Data Lake (built on Apache Hive, Apache Spark, and Apache Iceberg) stores protected data. Raw sensitive values are never written here: only tokenized representations persist in the lake.
Apache Atlas stores lineage and metadata. Future integration will have tokenized related information stored on Atlas.
The Data Analyst queries tokenized and de-tokenized data through standard SQL interfaces (Beeline, JDBC, or Apache Spark) with no change to existing query patterns. The UDF model connected to Spark/Hive engine makes tokenization entirely transparent to the analyst's tooling.
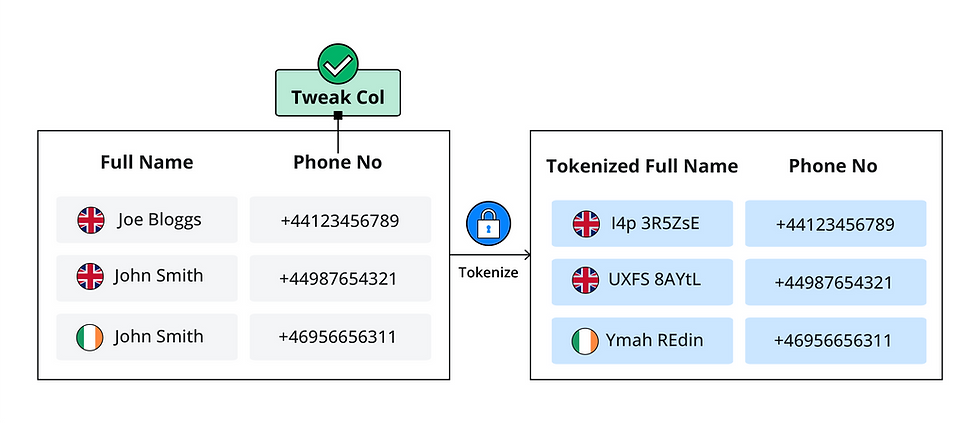
Reducing Correlation with FF1 tweak support
In some environments, organisations need an additional way to reduce the risk of token correlation between datasets.
SecureToken supports optional tweak values as an additional input into the tokenization process. This makes it possible for the same original value to produce different tokens in different business contexts, while remaining reversible when the correct controls and inputs are present.
That added flexibility gives security administrators more control over how tokenization behaves across different datasets and uses cases, especially where reducing correlation risk is a priority.
Built for Performance and Scalability
For high performance and scalability, SecureToken is deployed natively in the Cloudera platform. This means organisations can benefit from the same distributed model that supports large-scale data processing. Tokenization happens during active ingestion or ETL point or de-tokenization at query time, via UDF invocation.
There is no separate vault infrastructure to provision, synchronize, or scale independently. As the volumes and query concurrency of data grow, SecureToken scales with the underlying Cloudera platform in a cost-effective manner.
Designed to Fit Existing Enterprise Environments
Another core design goal for SecureToken is that tokenization operates in existing data infrastructure organisations already operate.
SecureToken supports native UDF-based integrations, standards-based APIs, and compatibility with multiple key management systems. It can be deployed across on-premises, cloud, and hybrid environments, giving platform teams flexibility in how they bring tokenization into their architecture.
This matters because enterprise security solutions are far easier to adopt when they work with existing tooling rather than forcing teams into a complete redesign.
Zero Trust Security and Governance
Security governance in SecureToken is continuous enforcement model, because threat landscape changes as data environments and access patterns evolve.
SecureToken’s Zero Trust architecture assumes that no system or user is trusted by default, enforcing verification at every operation boundary through identity propagation and authentication, profile as security policy, encryption key access control, and more.
All these audit records are captured before the operation result is returned to the caller. Every security action is governed by its immutable audit trail, with the compliance dashboard surfacing deviations and access events in real time for security teams and compliance auditors.
This gives organisations a stronger governance posture while reducing the risk of unnecessary data exposure.

Tying It All Together
Vaultless Tokenization is most effective when it does more than protect data. With the tight integration of Cloudera services, Bluemetrix team built a large-scale cost effective and highly secure tokenization solution. The centralised data protection provides a powerful tool to protect sensitive data and reduce compliance scope.
To start creating your own Cloudera native tokenization solution, we recommend that you read this technical blog, How to Secure PII in Motion with Cloudera + Bluemetrix SecureToken.
To learn more about SecureToken, request a demo here.


