Data Tokenization vs Data Masking vs Data Encryption: Know Everything Here
- Mar 27, 2024
- 5 min read
Updated: Apr 23, 2025
Data tokenization, data masking, and data encryption are three data security techniques that are often confused. Here's how they differ and the challenges you may encounter.
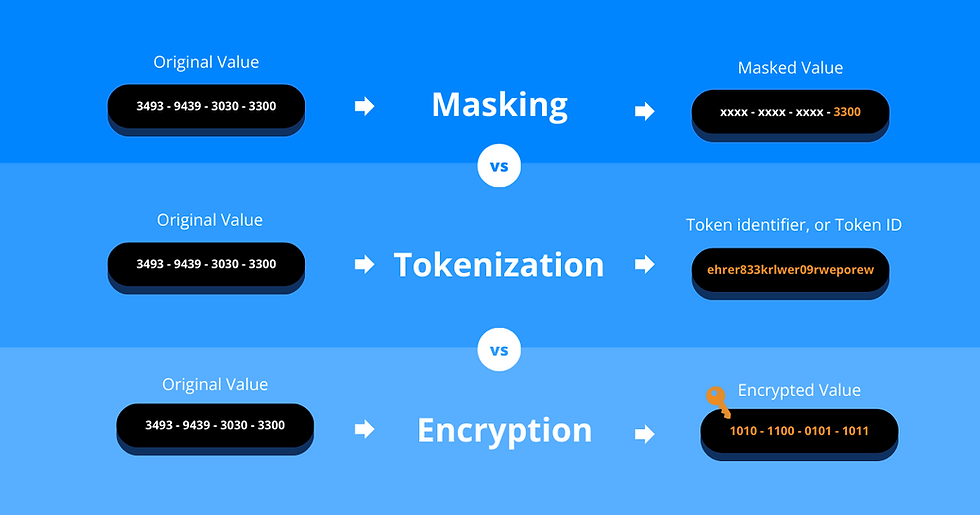
Data security involves three crucial pillars of protection: data tokenization, data masking and data encryption. While these terms are often used interchangeably, each plays a distinct role in fortifying data integrity and confidentiality.
As cyber threats continue to evolve, organisations must deploy the most appropriate data security solution for each project and use case. This blog aims to demystify these controls and highlight their differences to help you manage your data securely.
Jump to:
Defining Data Tokenization:
Data Tokenization is a security measure that replaces sensitive data with surrogate values called tokens. These tokens, acting as references, enable reversible retrieval of the original data through an authorised tokenization system – a process known as de-tokenization. While reversible schemes maintain token-to-data mappings, some implementations omit for irreversibility. Data Tokenization provides high security for data at rest and in motion, often deployed extensively within payment processing services.
There are two types of Tokenization techniques:
Stateless Tokenization:
This method operates without needing a mapping database/table to maintain token-to-value relationships.
It's efficient, scalable, and interoperable.
It is commonly used for one-time transactions or when consistent anonymisation is required without retrieval.
Stateful Tokenization:
It involves maintaining a reference or mapping between the token and the original value.
Requires a mapping database/table to store token-to-value relationships.
Used when there is a need to retrieve the original data from the token
Challenges:
It relies on a centralised token vault, which can be complex to implement and manage.
Advantages:
High security as original data remains within the storage premises; performance benefits over encryption; compliance with standards like PCI DSS, GDPR and BCBS 239.
Defining Data Masking:
Data masking, or data anonymization, refers to obscuring sensitive data with randomised values using various data shuffling and manipulation techniques. Crucial for privacy protection, this technique ensures that confidential information remains hidden from unauthorised access. Whether in testing environments or production systems, the irreversible nature of masking safeguards confidentiality without compromising data utility. Data masking is commonly used to protect PII data and comply with data protection regulations like GDPR, PCI DSS and BCBS 239.
Data masking can be performed in various ways:
Static Data Masking:
It involves altering sensitive data at rest, typically in a non-production environment, to permanently ensure privacy and data protection without altering the original data. The masked data must match the original data for accurate results and will be loaded into separate environments.
Dynamic Data Masking:
It hides real-time, sensitive data as users access or query it, preserving the original data at rest. This approach is well-suited for role-based data security and is commonly deployed in production systems to avoid separate storage. However, it may face consistency issues with multiple systems.
On-the-fly Masking:
Obscures sensitive data during its movement or transfer without retaining altered data in the database. This technique proves helpful in scenarios with space constraints or when data must swiftly transition between different source locations, making it ideal for continuous software development, skipping staging delays.
Unmasked database | Masked database | |
Name | John Smith | Jacky Murphy |
Address | 13 Patrick St. IE | 42 George Rd. De |
SSN | 123-78-1478 | 555-89-4587 |
DOB | 17-03-1983 | 20-08-1983 |
Credit Card Number | 4415 1230 000 8675 | 0301 9864 1640 3677 |
Challenges:
Masked data is often irreversible, making it unsuitable for scenarios where the original data needs to be retrieved.
Advantages:
It reduces the risk of data exposure, is easy to implement, and supports compliance with regulations like GDPR.
Defining Data Encryption:
Data encryption is the most commonly used method of encoding original data (unencrypted plaintext) into unreadable form (encrypted ciphertext) using an algorithm and a cryptographic key. The main difference between tokenization and encryption is that tokenization utilises tokens while encryption employs a 'secret key' for safeguarding data. Despite its reversible and breakable nature, encrypted data is treated as sensitive and considered a strong defence mechanism.
Depending on the keys used, there are primarily 2 types of encryption keys:
Symmetric Key Schemes – The same key encrypts and decrypts text.
Public Key Encryption—Encryption and decryption are performed using different keys, namely a public key (known to everyone) and a private key (secret key).
In terms of encryption algorithm:
Deterministic: Provide a single outcome for the same input; beneficial when sharing the data.
Non-Deterministic: Produces different outcomes for the same plaintext; hardly used in real-life scenarios.
Challenges:
Key management can be complex; encrypted data can be decrypted with sufficient resources.
Advantages:
Widely adopted and understood; can secure entire files or databases; supports data sharing.
Key Difference between Data Tokenization vs Data Masking vs Encryption
Understanding the nuances between Masking, Tokenization, and Encryption is pivotal for crafting data protection strategies that cater to diverse organisational needs and effectively mitigate evolving cyber threats.
Here's the comparison of Data Tokenization vs Data Masking vs Data Encryption:
Aspect | Data Tokenization | Data Masking | Data Encryption |
Purpose | Securely store or transmit without exposing | Protect sensitive information while maintaining usability | Protect data confidentiality during storage and transmission |
Reversible | Yes, when a mapping is available | No, once static masking is applied | Yes, reversible with encryption key |
Key Management | Requires tokenization system keys for mapping between tokens and original data. | Involves masking policies and keys to control the obfuscation process. | Utilises encryption keys for both encryption and decryption processes. |
Data Security Level | Strong, original sensitive data never leaves the organisation | Strong, original sensitive data remains hidden but retrievable | Strong, original sensitive data leaves the organisation, but in encrypted form |
Complexity | Data tokenization pipelines are less complex compared to encryption. | Data masking pipelines are more intricate due to defining masking policies and managing keys for obfuscation. | Data encryption pipelines can be the most complex, especially with large volumes. |
Coding and Domain Expertise | Tokenization involves tokenising libraries or services, potentially requiring less cryptographic expertise. | Data masking necessitates skilled data architects and governance specialists. | Data encryption demands expertise in cryptography, key management, and secure coding practices. |
Tools for Data Tokenization vs Data Masking vs Data Encryption:
Various tools and technologies support both data tokenization and data masking. Among the most used tools that seamlessly integrate with all ETL tools and facilitate the creation of a unified data environment are:
What's Next?
To sum up, the choice between tokenization, masking, and encryption hinges on an organisation's specific needs and context. Factors such as the nature of data, regulatory requirements, and the operational environment all contribute to determining the most appropriate data security method.
Masking, for example, is ideal for organisations seeking to balance privacy protection with data utility. On the other hand, Tokenization is better suited for organisations prioritising compliance, particularly with standards like PC1 DSS or GDPR, especially for long-term storage and analytics purposes. Encryption, meanwhile, is more appropriate for facilitating secure remote work scenarios by enabling the safe exchange of sensitive information among authorised users with access to encryption keys.
Here's a quick summary of the use cases and suggested approaches.
Use Case | Suggested Approach |
Test Environments | Masking |
Data Lake/Data Warehouse for Analytics | Masking |
GDPR or BCBS 239 Compliance | Tokenization |
Third-Party Data Sharing | Tokenization |
Payment Processing Systems | Tokenization |
Data Analytics | Tokenization |
Long-term Data Retention | Tokenization |
Unstructured Data | Encryption |
External Breach Prevention | Encryption |
Secure Data Exchange | Encryption |
Protecting Data At Rest | Encryption |
Bluemetrix's latest automation release revolutionizes data governance, security, and LakeHouse integration, ensuring seamless, continuous security management. Trusted by global leaders, Bluemetrix's data tokenization and masking solution, which is NIST—and FIPS 140-3 compliant—empowers organizations to innovate confidently while staying ahead of privacy provisions and penalties. Explore our product pages or connect with our team for firsthand experience implementing data governance and security control using Bluemetrix.

